
Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
NeurIPS 2025 Oral Best Paper
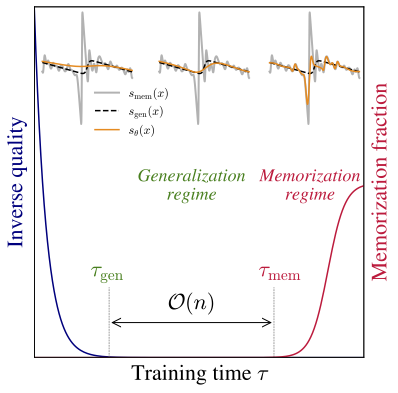
In this work, we investigate the role of the training dynamics in the transition from generalization to memorization in Diffusion Models. Through extensive experiments and theoretical analysis, we identify two distinct timescales: an early time $\tau_\mathrm{gen}$ at which models begin to generate high-quality samples, and a later time $\tau_\mathrm{mem}$ beyond which memorization emerges. Crucially, we find that $\tau_\mathrm{mem}$ increases linearly with the training set size $n$, while $\tau_\mathrm{gen}$ remains constant. This creates a growing window of training times with $n$ where models generalize effectively, despite showing strong memorization if training continues beyond it. It is only when $n$ becomes larger than a model-dependent threshold that overfitting disappears at infinite training times. These findings reveal a form of implicit dynamical regularization in the training dynamics, which allow to avoid memorization even in highly overparameterized settings.
Proceedings arXiv OpenReview Code
BibTeX
@inproceedings{NEURIPS2025_ceb7f3cc,
author = {Bonnaire, Tony and Urfin, Rapha\"{e}l and Biroli, Giulio and Mezard, Marc},
booktitle = {Advances in Neural Information Processing Systems},
editor = {D. Belgrave and C. Zhang and H. Lin and R. Pascanu and P. Koniusz and M. Ghassemi and N. Chen},
pages = {141266--141286},
publisher = {Curran Associates, Inc.},
title = {Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training},
url = {https://proceedings.neurips.cc/paper_files/paper/2025/file/ceb7f3cc876a6dcb15130a645b5a4507-Paper-Conference.pdf},
volume = {38},
year = {2025}
}